The last time we used a single hidden layer neural network, the results were promising, but this time we decided to take it a step further by using a Convolutional Neural Network (CNN). CNNs have become the backbone of modern computer vision systems, and they are particularly effective for tasks like facial keypoint detection.
Below is an illustration of a convolutional neural network, showcasing how the training process works alongside data expansion techniques:
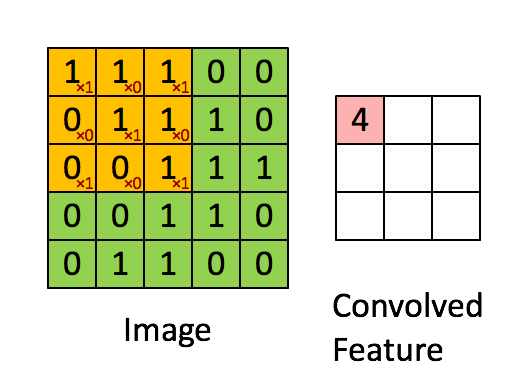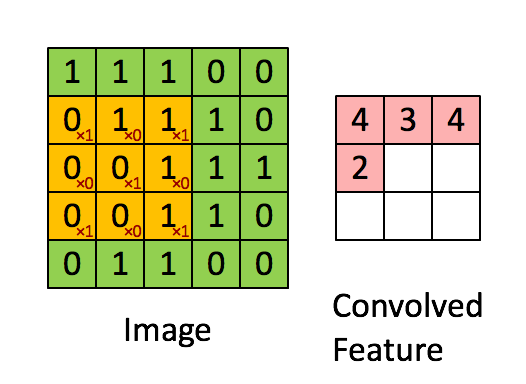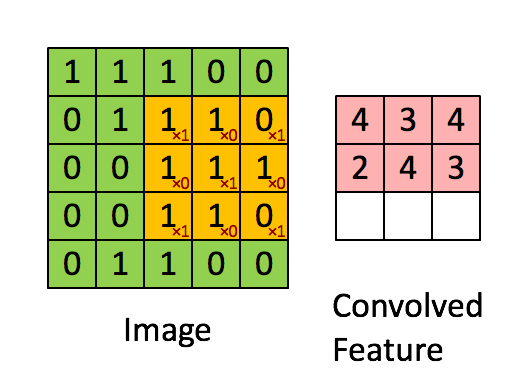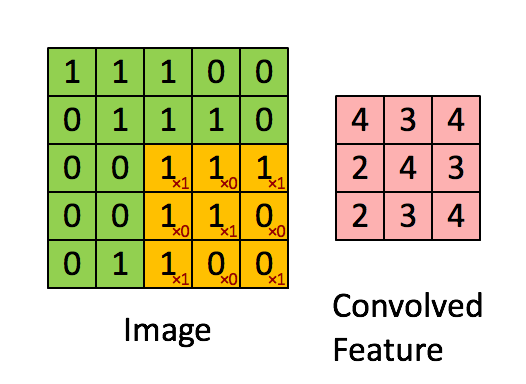
The figure above demonstrates the convolution operation, which is a fundamental building block of CNNs. The LeNet-5 architecture, one of the earliest successful CNN models, introduced several key concepts that are still widely used today. Unlike fully connected layers, convolutional layers reduce the number of parameters while preserving model performance through techniques such as:
1. **Local Receptive Fields**: Neurons in a convolutional layer only connect to a small portion of the previous layer, allowing the network to capture local patterns effectively.
2. **Weight Sharing**: Instead of having unique weights for each connection, the same set of weights (filters) is applied across the entire input, reducing computational complexity.
3. **Pooling Layers**: These layers downsample the feature maps, helping to reduce spatial dimensions and control overfitting.
To better understand locality and weight sharing, imagine that each neuron in a convolutional layer looks at a small patch of the input image. This allows the network to exploit the two-dimensional structure of images, making it more efficient and powerful for visual tasks.
When working with CNNs in frameworks like Lasagne, the input format changes significantly. Instead of using a flat vector of pixel intensities (like 9216 values), we use a 3D tensor in the form (c, 0, 1), where c represents the number of channels (e.g., 1 for grayscale, 3 for RGB), and 0 and 1 correspond to the width and height of the image. In our case, the input shape becomes (1, 96, 96), as we’re dealing with grayscale images of size 96x96 pixels.
A helper function called `load2d` is used to reshape the input into the correct 3D format:
```python
def load2d(test=False, cols=None):
X, y = load(test=test)
X = X.reshape(-1, 1, 96, 96)
return X, y
```
We are now constructing a CNN with three convolutional layers followed by two fully connected layers. Each convolutional layer is followed by a 2x2 max pooling layer. The first convolutional layer uses 32 filters, and the number of filters doubles after each convolutional layer. The fully connected layers contain 500 neurons each.
Interestingly, even without additional regularization techniques like dropout or L2 penalty, the small filter sizes (e.g., 3x3 or 2x2) naturally act as a form of regularization, helping to prevent overfitting.
Here’s the code for the network:
```python
net2 = NeuralNet(
layers=[
('input', layers.InputLayer),
('conv1', layers.Conv2DLayer),
('pool1', layers.MaxPool2DLayer),
('conv2', layers.Conv2DLayer),
('pool2', layers.MaxPool2DLayer),
('conv3', layers.Conv2DLayer),
('pool3', layers.MaxPool2DLayer),
('hidden4', layers.DenseLayer),
('hidden5', layers.DenseLayer),
('output', layers.DenseLayer),
],
input_shape=(None, 1, 96, 96),
conv1_num_filters=32, conv1_filter_size=(3, 3), pool1_pool_size=(2, 2),
conv2_num_filters=64, conv2_filter_size=(2, 2), pool2_pool_size=(2, 2),
conv3_num_filters=128, conv3_filter_size=(2, 2), pool3_pool_size=(2, 2),
hidden4_num_units=500, hidden5_num_units=500,
output_num_units=30, output_nonlinearity=None,
update_learning_rate=0.01,
update_momentum=0.9,
regression=True,
max_epochs=1000,
verbose=1
)
X, y = load2d()
net2.fit(X, y)
```
After training, we save the model using pickle so that it can be loaded later:
```python
import cPickle as pickle
with open('net2.pickle', 'wb') as f:
pickle.dump(net2, f, -1)
```
Training this CNN is significantly more resource-intensive than the previous network. Each iteration is about 15 times slower, and running 1000 epochs can take over 20 minutes, even with a good GPU. However, the improved performance makes the effort worthwhile.
Looking at the output, we see the shapes of the layers:
- InputLayer: (None, 1, 96, 96) → 9216 outputs
- Conv2DLayer: (None, 32, 94, 94) → 282,752 outputs
- MaxPool2DLayer: (None, 32, 47, 47) → 70,688 outputs
- Conv2DLayer: (None, 64, 46, 46) → 135,424 outputs
- MaxPool2DLayer: (None, 64, 23, 23) → 33,856 outputs
- Conv2DLayer: (None, 128, 22, 22) → 61,952 outputs
- MaxPool2DLayer: (None, 128, 11, 11) → 15,488 outputs
- DenseLayer: (None, 500) → 500 outputs
- DenseLayer: (None, 500) → 500 outputs
- DenseLayer: (None, 30) → 30 outputs
Next, we observe the training and validation losses over iterations:
| Epoch | Train Loss | Valid Loss | Train / Val |
|-------|------------|------------|-------------|
| 1 | 0.111763 | 0.042740 | 2.614934 |
| 2 | 0.018500 | 0.009413 | 1.965295 |
| 3 | 0.008598 | 0.007918 | 1.085823 |
| ... | ... | ... | ... |
| 1000 | 0.001079 | 0.001566 | 0.688874 |
The results after 1000 epochs are impressive. The final RMSE is:
```python
>>> np.sqrt(0.001566) * 48
1.8994904579913006
```
This shows that the CNN has significantly outperformed the previous model, proving the effectiveness of convolutional architectures in this task.
Network Cabling Products
We offer service for network cabling products in following series: 19" Floorstanding Cabinets in 18U to 45U, Wall mount cabinets and frames, regular patch panel in 6port to 48port,hot sale on 24port cat.5e UTP patch panel,24 port angle patch panels, over 30 kinds of various horizontal and vertical wire management panel,Cat.5e and Cat.6 Patch Cords, toolesskeystone jacks accordingly.

Network cabling products Quality Control Instruction:
To offer a perfect product, we every worker pay attention to each detail of our network cabling products. With our company aim, first in our purchase department, our purchaser compares strictly in raw material suppliers to control cost but keep quality, our mold workshop makes inspection before plastic parts turned to production line .Before installation, our production line first will inspect on plastic parts and other components. During production procedure ,there is tester in steps according different products needs. After installation, the Quality Control members will make a full inspection on characters, appearance according our specification.
19" Floor Cabinet, Cat.5e Patch Panel, Cable Management Bars, Angled Patch Panel, Cat.6a Sheilded Keystone Jack, Cat.6a UTP Keystone Jack, Network Cabling Products, Cat5 Network Cable, Patch Panel.
NINGBO YULIANG TELECOM MUNICATIONS EQUIPMENT CO.,LTD. , https://www.yltelecom.com
