The last time we used a single hidden layer neural network, the results were promising, but this time we've taken a step further by implementing a Convolutional Neural Network (CNN). CNNs have become the backbone of modern computer vision systems and are especially effective for tasks like facial keypoint detection.
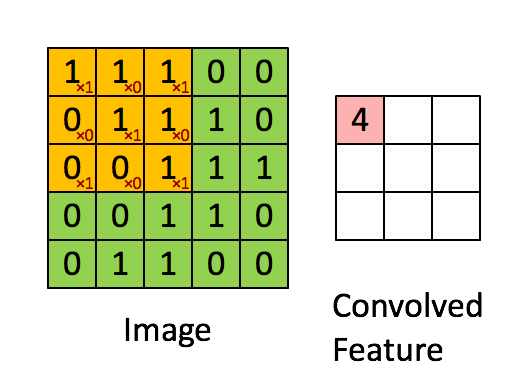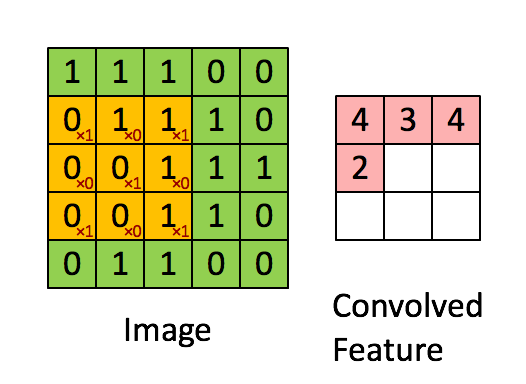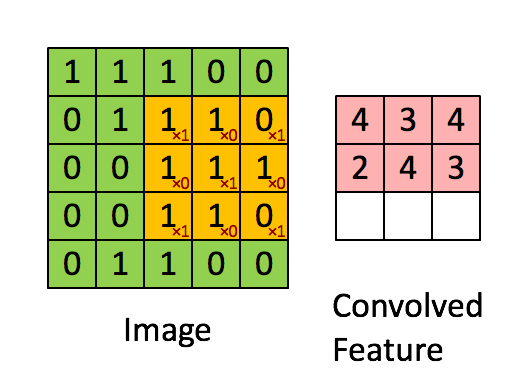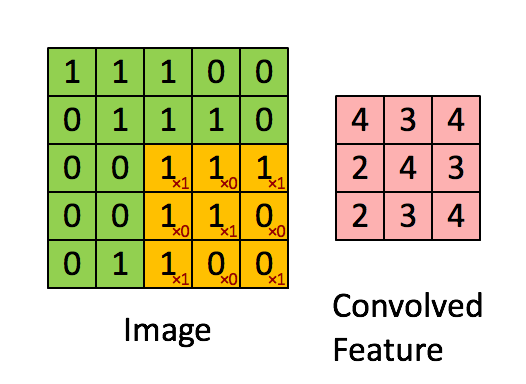
Below is an illustration of a convolutional neural network, showcasing its training process and data expansion techniques:
The fiber cutter is used to cut fiber as thin as hair. After hundreds of times of amplification, the cut fiber is observed to be flat before discharging the fuse.
The material of fiber is quartz, so the material of fiber cutting knife blade is required.
Adaptive fiber: single or multi-core quartz naked fiber;
Suitable for fiber cladding :100-250um diameter.

Fiber Optic Cleaver, Optical Fiber Cleaver, Fiber Optic Cutter, Hardware Networking Tools
NINGBO YULIANG TELECOM MUNICATIONS EQUIPMENT CO.,LTD. , https://www.yltelecom.com