The contest's main goal is to identify four mathematical expressions that resemble handwriting. Participants are required to develop an algorithm capable of recognizing mathematical formulas from images and computing their results across 100,000 pictures filled with various types of noise. In the finals, the competition becomes more challenging, with higher scoring thresholds and more complex calculations. The final recognition rate is the key metric used to evaluate the performance of the algorithm.
This section will elaborate on all the strategies I employed to tackle the four basic operations in the preliminary round.
Problem Description
At its core, this competition revolves around an OCR (Optical Character Recognition) challenge. In simpler terms, it involves converting images containing text into actual text data.
Data Set
The preliminary dataset consists of 100,000 images, each measuring 180x60 pixels, along with a corresponding text file named labels.txt. Each image contains a mathematical expression that includes:
- Three operands: three integers ranging from 0 to 9;
- Two operators: which can be +, -, or * representing addition, subtraction, and multiplication;
- Zero or one pair of parentheses: either no parentheses or a single pair.
The image filenames range from 0.png to 99999.png. Here’s a sample image (only one is shown here):

The labels.txt file contains 100,000 lines, each line corresponding to a formula and its computed result for the respective image. The formula and result are separated by a space. For example, the content of the sample image would look like this:
(3-7)+5 1
5-6+2 1
(6+7)*2 26
(4+2)+7 13
(6*4)*4 96
Evaluation Index
The official evaluation metric is accuracy. During the preliminary round, only integer addition, subtraction, and multiplication are considered, and the result must be an integer. Therefore, both the correct sequence of characters and the accurate calculation result are necessary.
In addition to using the official accuracy metric, we also utilized CTC loss as a secondary evaluation method during training.
Data Augmentation Using Captcha
Although the official dataset of 100,000 images can be used directly for training, generating additional random data using a captcha generator based on the same rules can significantly improve model performance. According to the problem constraints, each label must consist of three numbers, two operators, and optionally zero or one pair of parentheses. It is straightforward to write code for such a generator since only valid parentheses combinations are allowed.
Generator
The generator follows simple rules:

I believe most people can understand it. However, while writing the article, I came up with a better approach:

When generating equations, there is one important detail to note: all minus signs in the preliminary set are fine, but when generating images using the captcha library, the minus sign often appears too thick. To address this, I modified the _draw_character function in the .py file to skip resizing when the character is a minus sign, preventing it from becoming too thick.
We then generated some captcha images for the four operations:


The image above was generated by the original generator, and you can see that the minus sign is very thick.
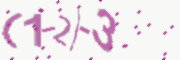
The image above shows the modified generator, where the minus sign is not thickened.
Model Structure



The model structure is similar to previous designs, but with a few modifications. We increased the number of convolutional kernels, added batch normalization (BN) layers, and made minor adjustments to support multi-GPU training. If using a single GPU, simply remove the base_model2 = make_parallel(base_model, 4) line.
The BN layers help speed up training, and the experimental results were very promising, with faster convergence of the model.
Visualization of base_model:

Visualization of the full model:
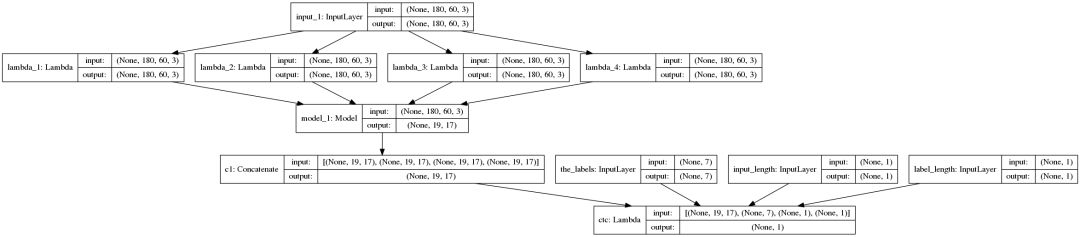
Model Training
After several tests, I decided to remove the evaluation function because achieving 100% accuracy on the validation set was already possible. From that point on, I focused solely on val_loss. Based on earlier experiments, I found that more training data led to better performance, so I trained the model for 50 epochs with 100,000 samples per epoch. The model converged well after about 10 epochs.
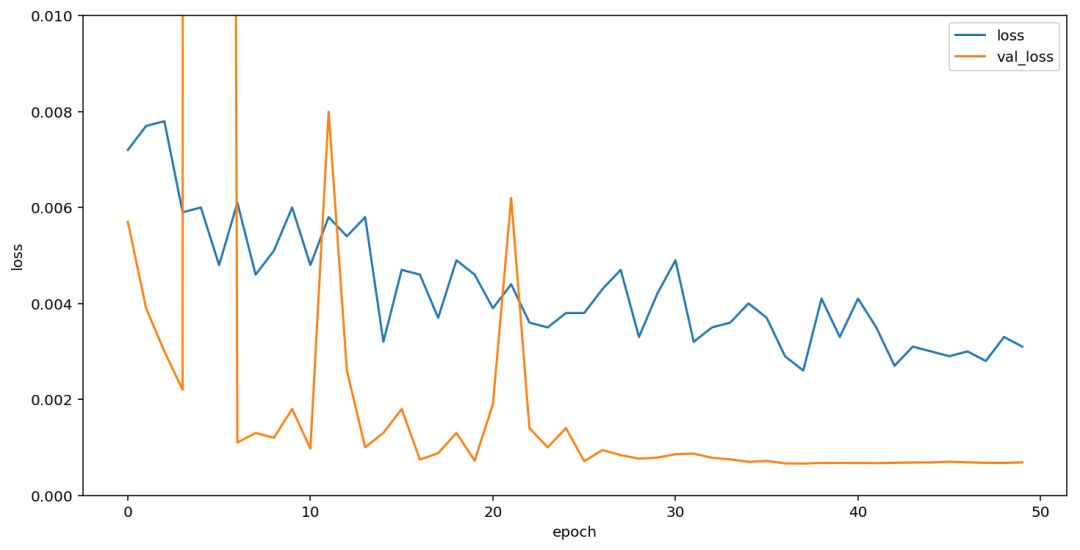
As seen in the figure, the model is divided into four parts and runs in parallel on four GPUs. The results are combined, and the final CTC loss is calculated for training.
Visualizing Results
We visualized the generated data and observed that the model performed very reliably, with almost no errors.
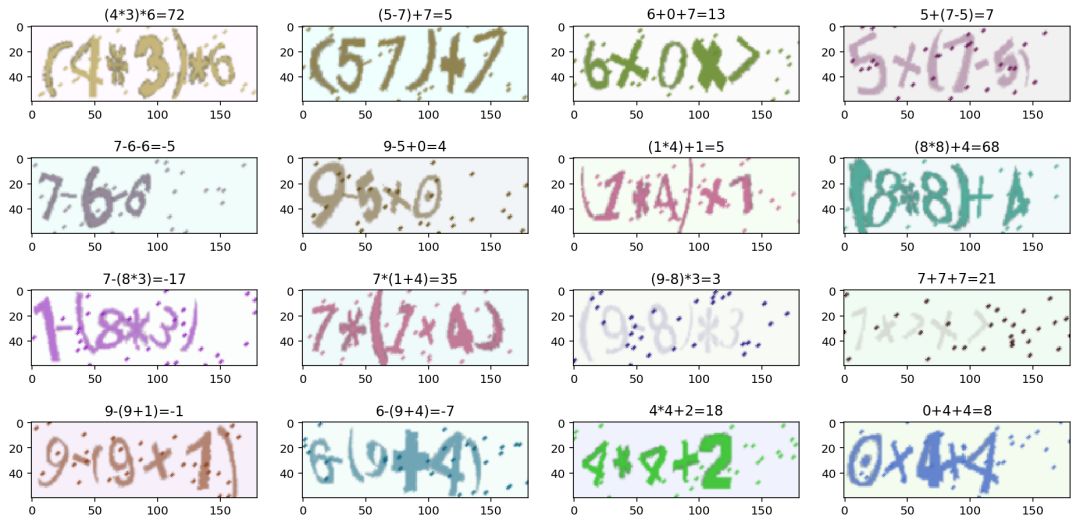
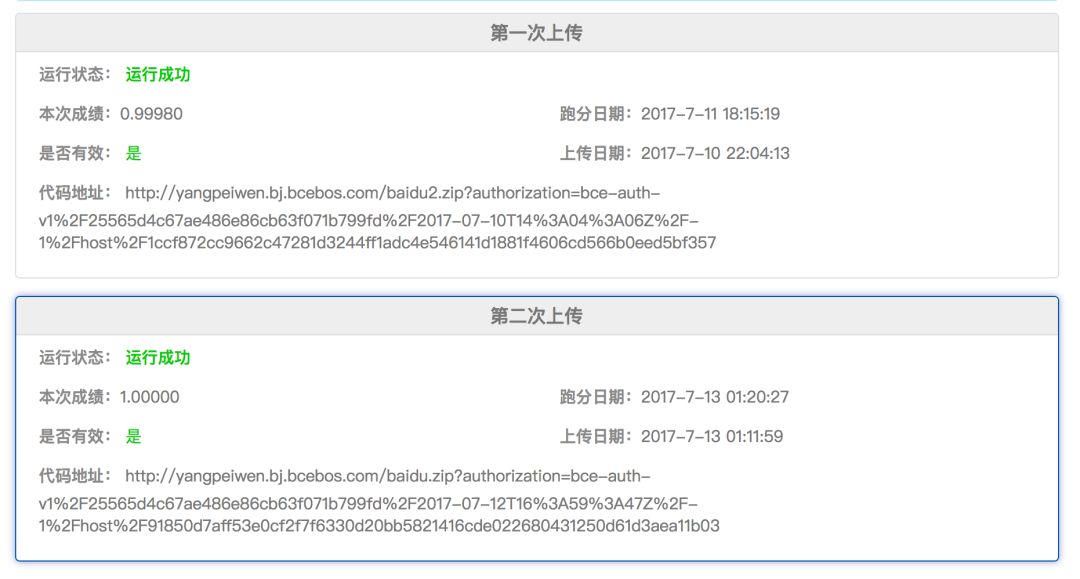
After packaging the model into a Docker container, we submitted it to the competition system. After over ten minutes of processing, we achieved a perfect score of 1.0.
Summary
The preliminary round was relatively easy, allowing us to achieve a high score. However, the official competition later increased the difficulty, expanding the preliminary test set to 200,000 images. Our model managed to achieve a score of 0.999925, indicating room for improvement. Possible enhancements include further increasing accuracy, fully training the model, and ensembling predictions from multiple models.
Challenges in the Extended Dataset
On the extended dataset, we encountered some images that were difficult to recognize and compute correctly. For instance, the following indices had issues: [629, 2271, 6579, 17416, 71857, 77631, 95303, 102187, 117422, 142660, 183693]. Let's take 117422.png as an example:

It's hard to read the image with the naked eye, but after applying some image processing techniques, the true content becomes visible:

After processing, we obtained the following result:

However, some images, such as 142660, still could not be accurately recognized even after preprocessing. This might be due to a rare bug in the program. As a result, we did not achieve a perfect score in the preliminary round despite our best efforts.
This battery is for replacing lead-acid battery, it has the standard appearance and size as well as capacity, but longer cycle life and high energy and good charge and discharge performance.
Capacity:100AH/150AH/180AH/200AH/250AH.
Voltage:12.8V, cycle life is more than 2000 times, also can customize the capacity.
Lifepo4 Battery,Lifepo4 Battery 12V,Solar Battery Pack,180Ah Lithium Mobile Battery,2304Wh Lithium Battery Power Bank,Lead Acid Replacement Battery
Enershare Tech Company Limited , https://www.enersharepower.com